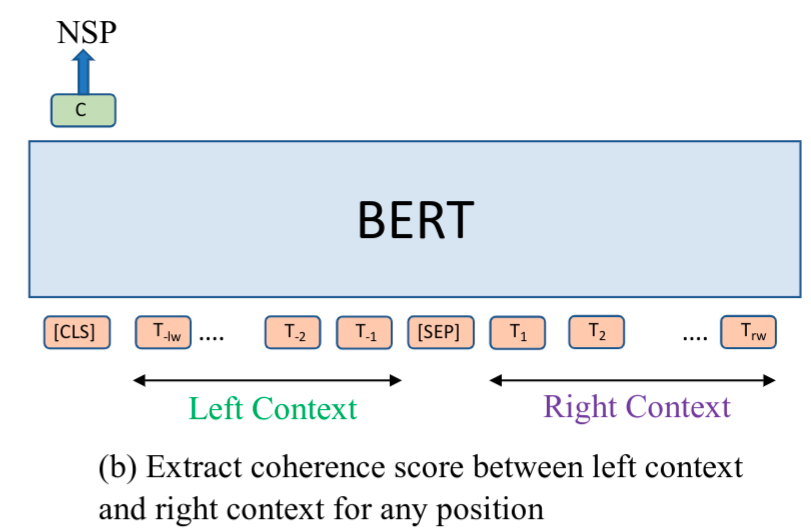
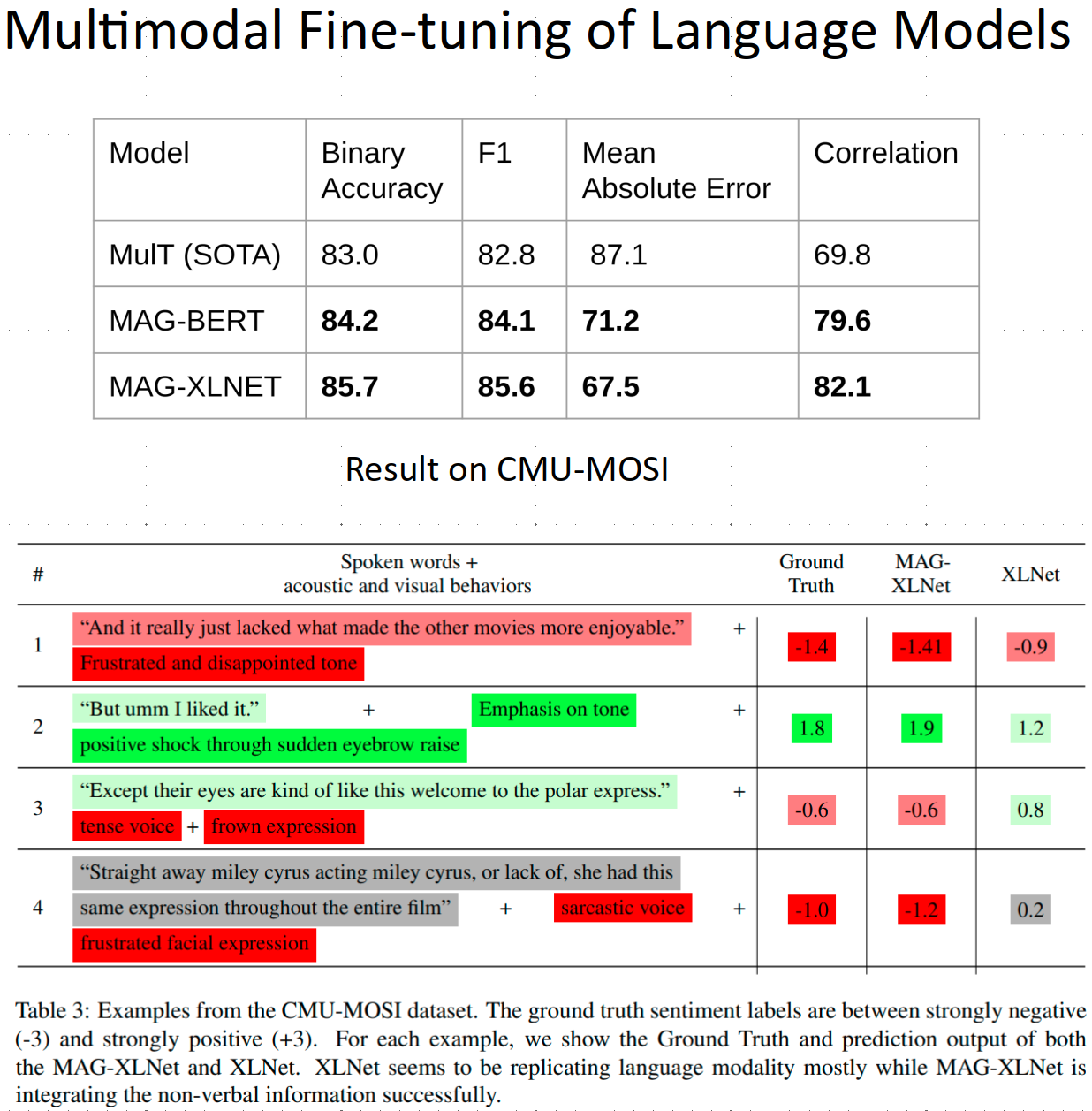
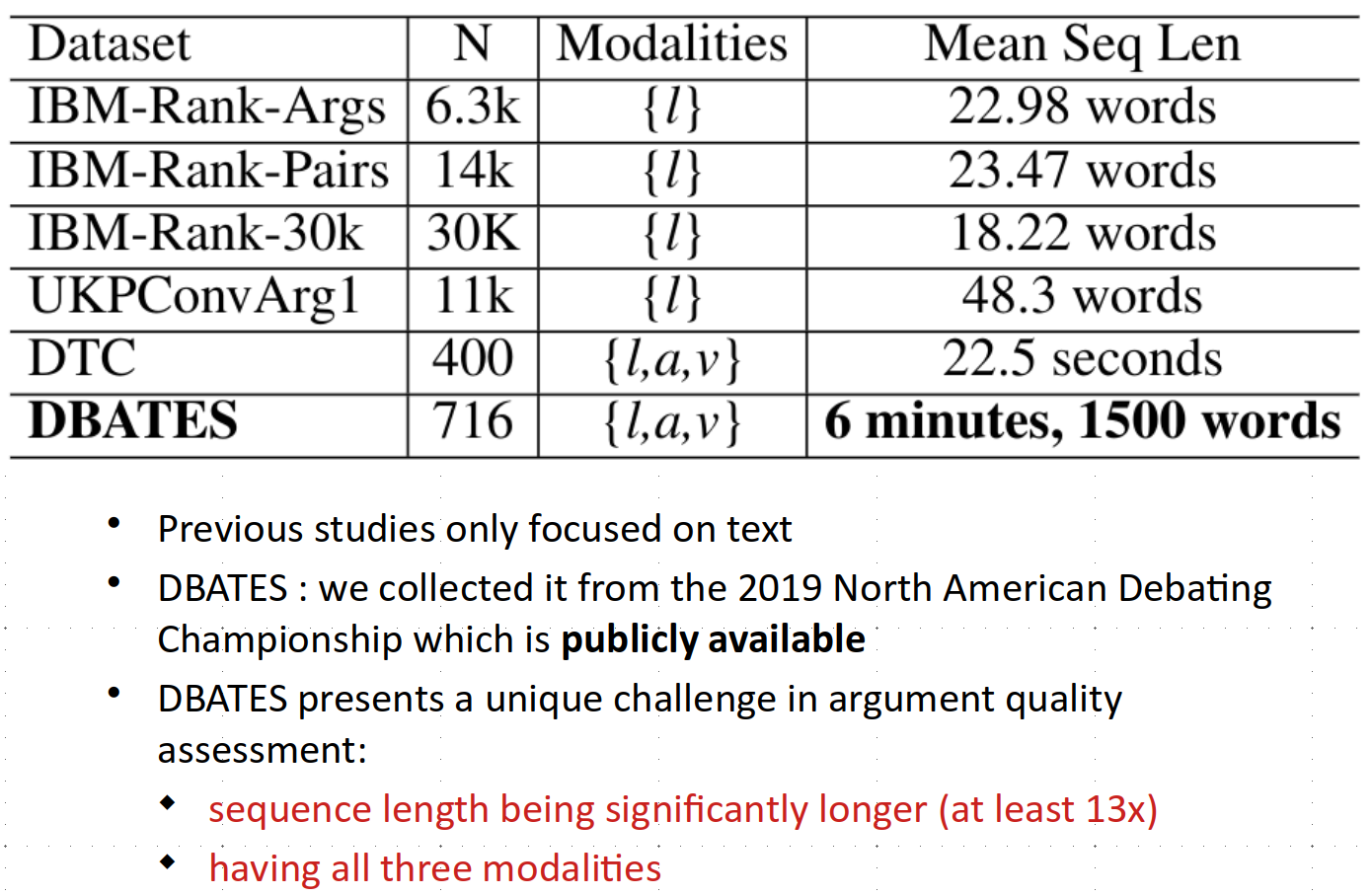
Kamrul Hasan
I am a PhD candidate at the Univcersity of Rochester, USA. I received my MS degree in Computer Science from the University of Rochester in 2018 and B.Sc. in Computer Science and Engineering from Bangladesh University of Engineering and Technology in 2014. My research focused on theoretical and empirical aspects of multimodal machine learning. It is concerned with joint modeling of multiple modalities (language, acoustic & visual) to understand human language as it happens face-to-face communications. My research work spans the following areas: multimodal representation learning, humor, sentiment, argument & credibility understanding in video utterance. My supervisor is Ehsan Hoque. Resume